A verifier loop beats a faster local model
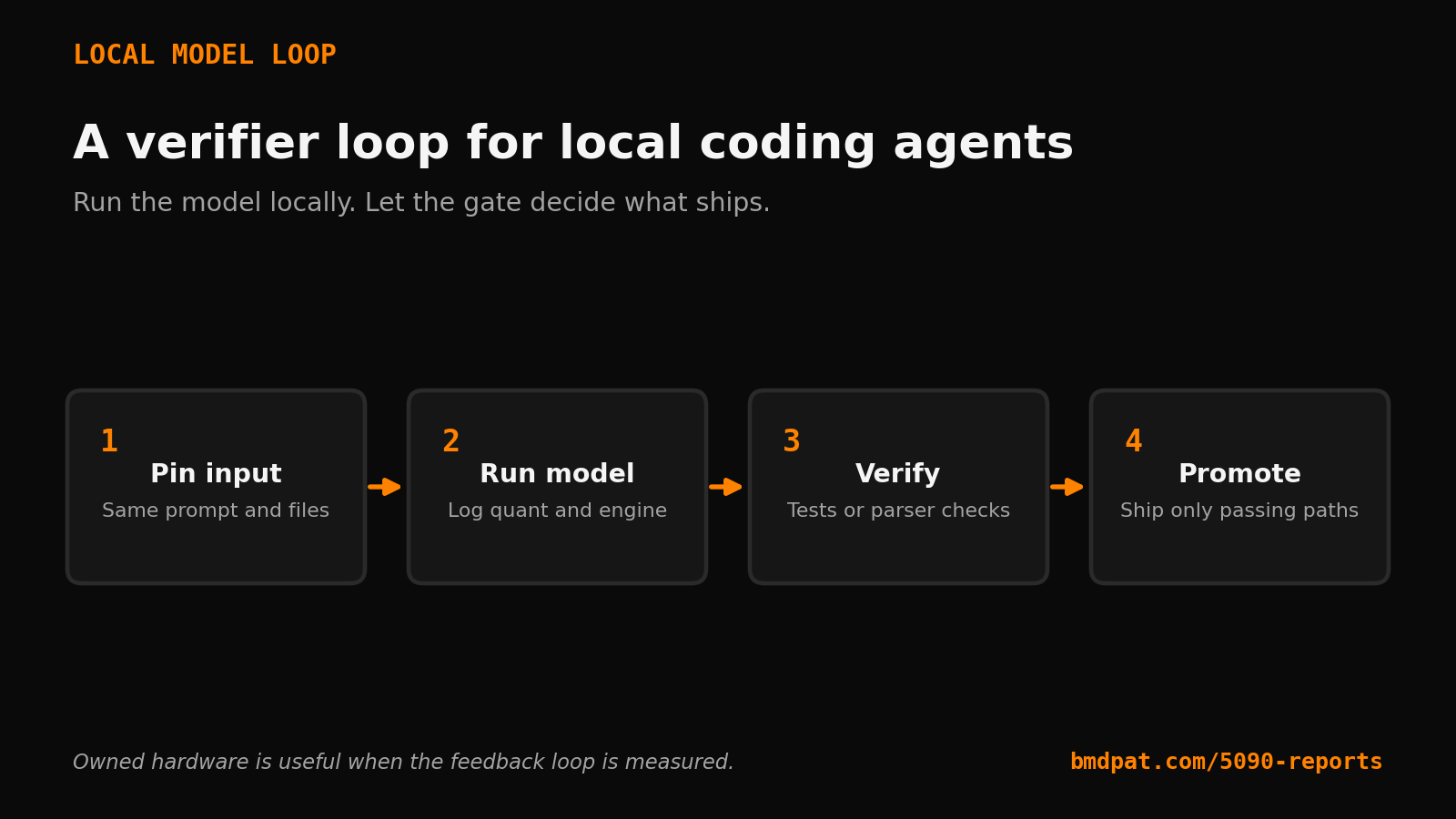
Local LLMs are useful when the loop proves the output, not when the benchmark looks good. This is the small gate I use before a local coding agent gets more rope.
I like fast local models. I do not trust them just because they are fast.
On July 2, my 5090 report had a real local row for Llama 3.1 8B running through Ollama. It used a Q4_K_M quant, a fixed local-agent instrumentation prompt, 69 input tokens, 128 output tokens, and recorded 216.89 tokens per second. That row mattered because it came from a fixed workload, not a demo that only looked good once.
Summary: Local model development needs a repeatable gate: fixed input, measured run, verifier, recorded row, then promote or block. A local LLM can be private and cheap for repeated work, but only a checked output earns automation.
Canonical URL: https://bmdpat.com/blog/local-model-verifier-loop-2026
What should a local model prove before it gets more work?
First, it should prove the same thing twice.
I want the same prompt, same files, same max tokens, same temperature, and the same tool allowance. If the local model needs a lucky run to pass, it is not ready for automation. It might still be useful for drafting. It should not write files, open PRs, update ledgers, or touch a customer workflow without a gate around it.
Why is speed not enough for local AI agents?
Speed is only one row in the table.
The July 2 5090 row told me local inference could move fast on that small instrumentation workload. It did not prove the answer was correct. It did not prove the output shape was stable. It did not prove the next run would survive a longer context, a different file, or a tool call.
That is the trap with local models. You get a fast answer and start treating the machine like an employee. It is not an employee. It is a probabilistic text engine with local privacy and nice latency. The verifier is what turns that into a usable agent path.
What does the verifier actually check?
The verifier should check the thing you would check by hand.
For a coding agent, that might be unit tests, type checks, lint, a parser check, or a command that proves the file it changed still loads. For a report agent, it might require specific fields: model, quant, engine, input tokens, output tokens, tokens per second, power if measured, source file, and verdict.
The point is not to make the model smarter. The point is to make the system harder to fool. If the model writes pretty text but misses the required fields, the row fails. If it returns malformed JSON, the row fails. If the command errors, the row fails.
How should I record local model runs?
Write down both passes and failures.
A useful row is small: timestamp, model, quant, engine, workload, input tokens, output tokens, speed, verifier, and verdict. Add watts or VRAM only when you measured them. If you did not measure a value, leave it blank or mark it unknown. Do not invent it because the table looks better full.
My Phase 3 starter metrics recorded unsloth/llama-3.1-8b-bnb-4bit, a local Unsloth route, 6.3 GB VRAM, and 42 seconds in its rows. I do not treat that as proof of a finished trained model. I treat it as proof that the measurement shape exists and can be repeated.
When should a local model get promoted?
Promote the path, not the model.
A model that passes summarizing a log does not automatically get permission to edit a repo. A model that passes JSON extraction does not automatically get permission to send email. Each workflow needs its own gate because each workflow has a different blast radius.
My rule is simple: the model can do the next job only after the current job has a verifier and the failures are named. If the failure mode is still mysterious, keep it in draft mode. If the verifier catches the bad output and the good output survives repeated runs, then the local path earns more rope.
What breaks when you skip the verifier?
You get fast wrong answers.
That is worse than slow wrong answers because speed makes the damage easier to repeat. A local model can write the same bad file ten times without an API bill yelling at you. It can also keep private data on your hardware while still corrupting your own workflow.
Local-first does not mean trust-first. It means the data, model, logs, and verifier can live where you control them. The verifier is the part that makes the control useful.
Accompanying prompt
What the prompt does: This prompt turns a local model test into a measured verifier loop before the workflow gets more permission.
Copy/paste this prompt:
Copy-ready prompt
Paste the exact block into your coding agent.
No article chrome, no footnotes, no formatting drift.
Copy the block above.
If you are wrapping local or API agents with budget, token, and rate limits, try AgentGuard: https://bmdpat.com/tools/agentguard
Get the local AI lab notes
Benchmark rows, VRAM fit checks, quant choices, and what actually runs on consumer GPUs. M-F, only when there is something worth sending.
Patrick Hughes
Building BMD HODL — a one-person AI-operated holding company. Nashville, Tennessee. Twenty-Two agents.
More writing
- 5 min
How I Make Local Model Runs Fail Safely On A 5090
A local model run should prove its safety path before it proves a score. Here is the small guardrail loop I use on my RTX 5090 for QLoRA starter work.
- 5 min
How to Make a Local QLoRA Starter Fail Safely
A local QLoRA starter should prove data, GPU safety, metrics, tests, and blockers before it claims progress. Here is the small loop I use on owned hardware.
- 5 min
How to Run Local LLM Verifier Loops on Owned Hardware
A local LLM workflow needs more than a model prompt. It needs a verifier loop that proves the file, command, URL, or report changed before the agent claims done.